
Presentation at Euromech Colloquium 662
Euromech Colloquium “Physics-enhanced machine learning and data-driven nonlinear dynamics”
My name is Giorgio L. Morales Luna. I am a researcher specializing in Symbolic Regression, Explainable and Interpretable Machine Learning, and Uncertainty Quantification. I earned a Ph.D. in Computer Science at Montana State University, as a member of the Numerical Intelligent Systems Laboratory (NISL). I hold an M.S. in Computer Science from Montana State University and a B.S. in Mechatronic Engineering from the National University of Engineering in Peru.
My research aims to advance transparent machine learning techniques that support scientific discovery, decision-making under uncertainty, and data-driven exploration across disciplines such as physics, biodiversity, and engineering. For a complete Academic CV, please visit here.
Ph.D. in Computer Science
Montana State University
Graduate Certificate in Artificial Intelligence
Montana State University
M.Sc., Computer Science
Montana State University
B.Sc., Mechatronics Engineering
National University of Engineering (Lima, Peru)
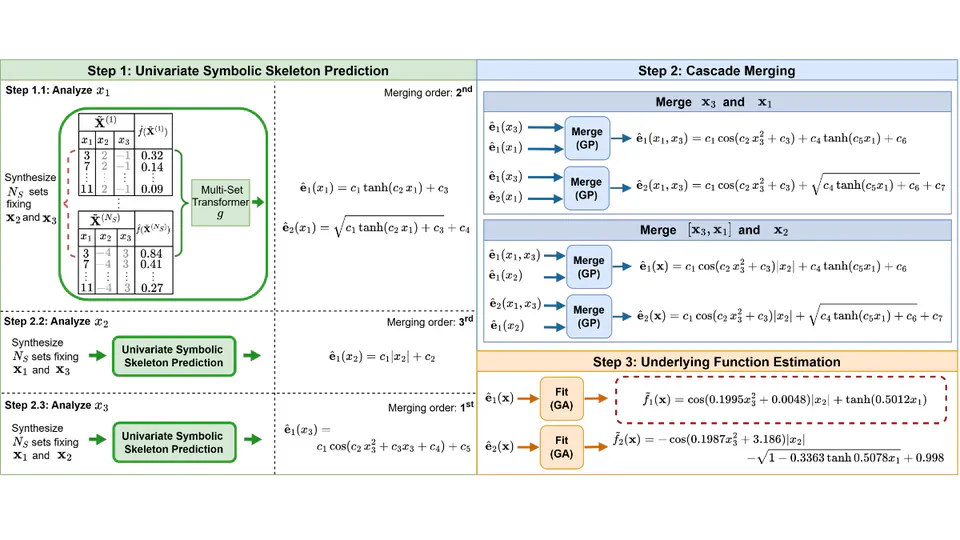
My current research focuses on Symbolic Regression, leveraging the advantages of deep learning techniques (e.g., transformer models) and evolutionary algorithms to distill experimental data into analytical equations that serve as causal explanations for the observable world. The aim is to offer an alternative to the use of black-box models and an avenue for the automated discovery of explanatory and causal models from observed data.
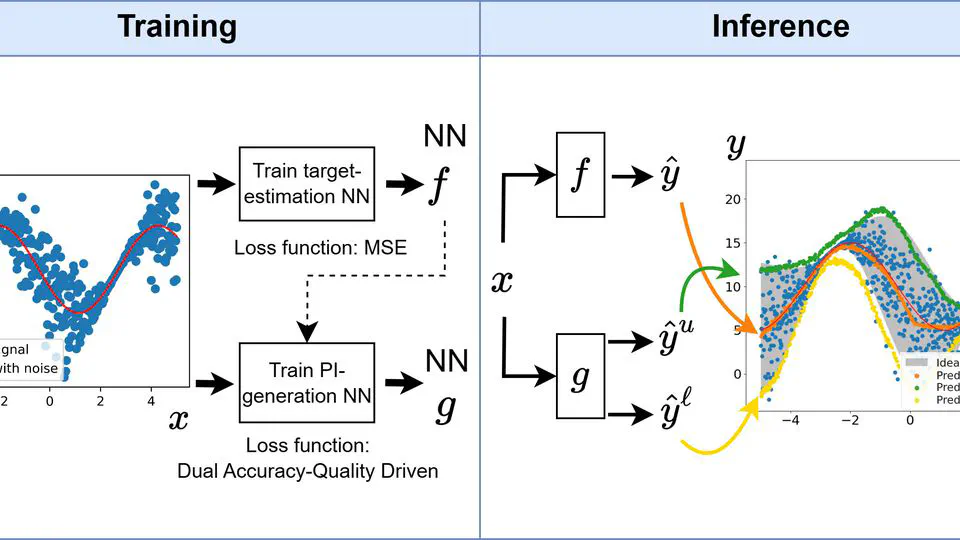
I am also working on uncertainty quantification and adaptive sampling techniques for epistemic uncertainty minimization.
Please reach out to collaborate 😃

Euromech Colloquium “Physics-enhanced machine learning and data-driven nonlinear dynamics”
International Joint Conference on Neural Networks (IJCNN)
I moved to the UK and will begin a new position at Aston University
Epistemic Intelligence in Machine Learning (EIML@EurIPS 2025)
I completed my graduate program and was awarded the PhD degree
I received this award during the “2025 Gianforte School of Computing Awards” at Montana State University
I received this award during the “2025 Research Celebration - Celebrating Creativity” ceremony




